一个基于electrong-vite的大日志文件浏览、过滤应用
背景
通常在APP和h5混合架构下,前端h5日志通过js-bridge来将应用日志打印到APP日志中,但是由于公司的APP日志和h5日志混合在一起,并没有特别针对h5日志进行归类打印,同时由于APP日志可能过于庞大,几十MB至几百MB的日志文件都有,所以当前端想要通过日志文件去梳理业务流程、排查线上问题时,面对几十、几百万行的日志数据难以快速过滤和筛查,且由于APP日志和前端h5日志混合在一起,导致前端h5日志之间可能充斥着大量APP的日志,在定位时前端日志文件区间跨度非常之大,从而在进行问题排查时较为痛苦且效率无法提升。
所以,在思考了上述排查前端日志时所面临的痛点后,觉得可以考虑实现一个对日志文件的数据过滤的应用。
ps:我通常使用vscode来浏览日志数据并排查问题。vscode中也有类似的插件支持对文件进行筛选,例如Filter Lines插件,他能同时支持字符串和正则,并且可以通过添加过滤配置文件来精细化的筛选出你想要的数据,一般情况下也能满足对日志数据的过滤需求。不过基于种种原因(例如vscode插件对大日志数据文件的限制),最后我还是想要尝试自行实现一个日志过滤应用。
需求
面对上面的痛点,通常有两个方面可以提升日志排查的效率和体验:
- 针对需要排查的目标日志散落在各处的问题,实现一个对目标日志文件进行过滤并且能够浏览其过滤结果的功能
- 针对日志排查效率,可以在日志过滤的基础上,实现针对具体业务的日志分析工具
第一点是整个应用的基础,故先主要实现该功能,当浏览和过滤功能完善后,后续的日志分析则可以自行根据业务需要去定义和展示。
方案
如果仅仅只是对于文件的浏览和过滤,那么整个流程就可以先简单定义:
- 通过electron打开一个文件,读取文件的数据
- 处理文件数据
- 在渲染进程展示文件数据
实现过程
日志文件的读取
作为web应用,我们通常可以使用下面两种方式来读取文件数据:
- 对于普通的web来说,我们可以通过input来选择文件并通过file相关的API来读取文件中的内容
- 在electron中你也可以选择使用electron提供的dialog对象并配合node的fs模块来读取文件内容,这两种方案都可以
不过这里因为明确其桌面应用的特性,后续也可能针对文件做一些更底层的操作和处理,所以,我选择了使用第二种方案,用election提供的API来打开和读取文件中的数据。
数据形式
在读取完日志数据后,我是直接以string文本字符串的形式读取的,并通过split来分割换行符来将每行日志数据存储为一个字符串数组。
日志元数据信息
日志元数据其实在这里暂时只包含了换行信息,因为在渲染进程显示日志数据时,也需要根据换行来区分每一行的日志数据,并且在过滤时也是针对的每一行日志数据来进行过滤。
在最开始的时候,由于我是直接通过字符串的split来分割每一行的数据,故这里的元数据其实没有必要,不过在后续的优化方案中,日志数据的形式有所变化,会单独处理日志元数据信息,这个我们下文再详细介绍。
日志数据浏览
单在electron主进程读取完并处理好日志数据后,在渲染进程需要展示该日志文件的数据,主进程会使用一个map保存当前打开日志文件,渲染进程通过ipc通信来展示打开过的日志文件列表。
当渲染进程决定浏览某个日志时,会通过ipc获取那个日志文件的所有数据(一个字符串数组),并通过虚拟滚动库来展示。
ps:通常如果你要显示大数据内容,通常都会使用到虚拟滚动相关的库,这里不再赘述。
过滤
由于渲染进程通过ipc获取到了日志文件的字符串数组,那么如果仅按照纯文本来过滤的话,则直接遍历整个日志文件的字符串数组,通过include来过滤每一行日志数据中是否包含需要过滤的字符串,然后展示其过滤后的字符串数组即可。
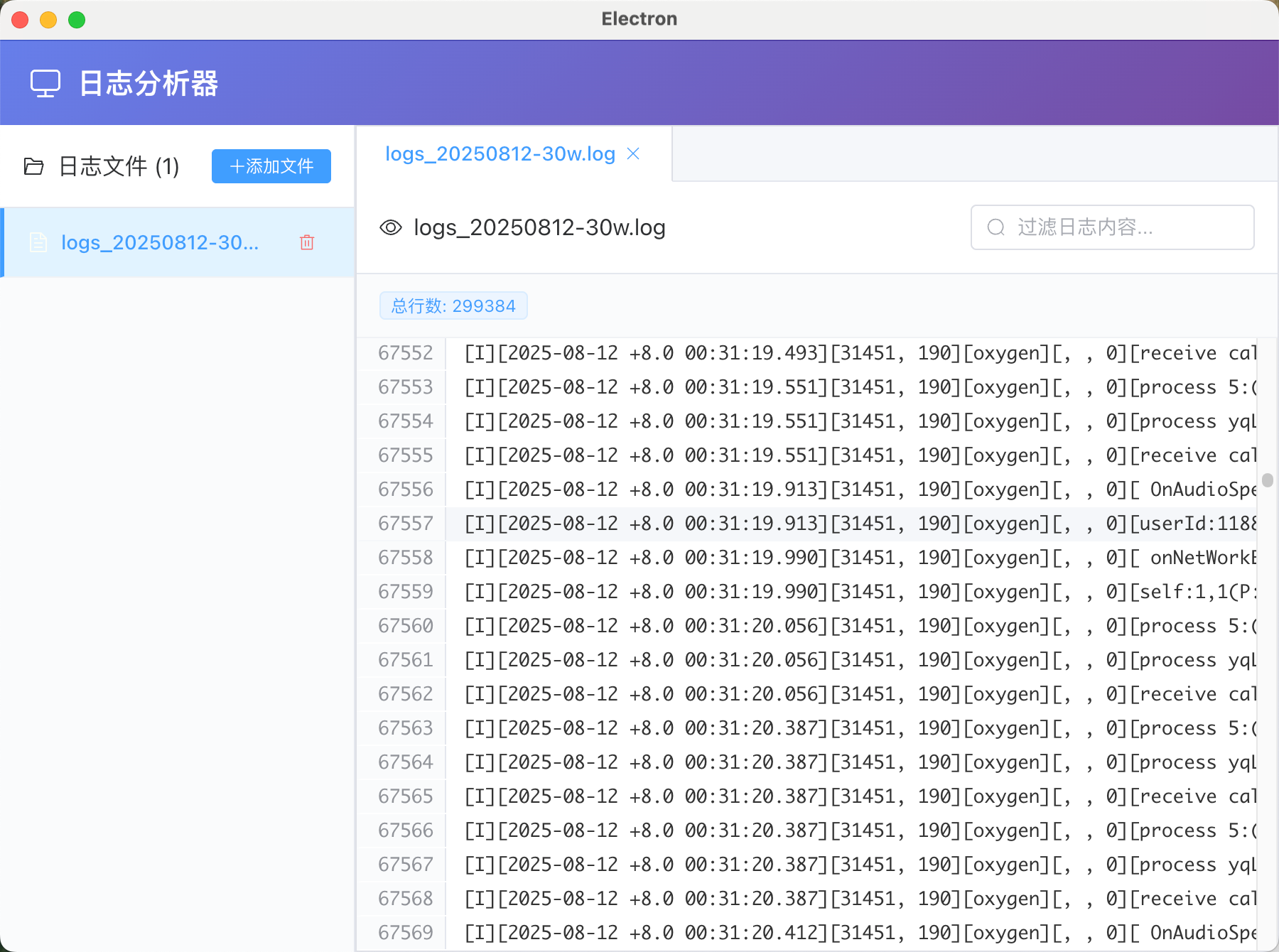
这是当时实现的页面截图:
优化
从上面的实现上来说,其实整个流程非常简单,没有什么难度,针对一般的日志文件,基本上整个流程就是:
- 通过electron的dialog对象和fs来读取文件内容
- 使用split来按行分割日志文本数据,并存储为一个string数组
- 渲染进程要浏览某个日志文件,则通过ipc获取这个日志文件的所有字符串数组并通过虚拟滚动展示即可
- 过滤时,也直接通过filter和include方法来遍历日志文件的字符串数组并展示过滤后的结果
如果日志文件比较小,比如只有几MB大小,那么其实问题也不大,不管是性能还是内存啥的都没啥压力。不过,如果是几十MB或者几百MB甚至上GB的日志文件,那么上面的一把梭方案可就撑不住,不管是性能上的还是内存上的。
所以,针对大文件的日志数据,我需要继续对整个流程中的实现进行一些优化。
内存问题
我们通过node的--inspect参数并结合chrome的远程调试来看看如果打开一个380MB左右的日志文件,那么会占据多少内存。
Chrome DevTools主进程内存面板和快照:
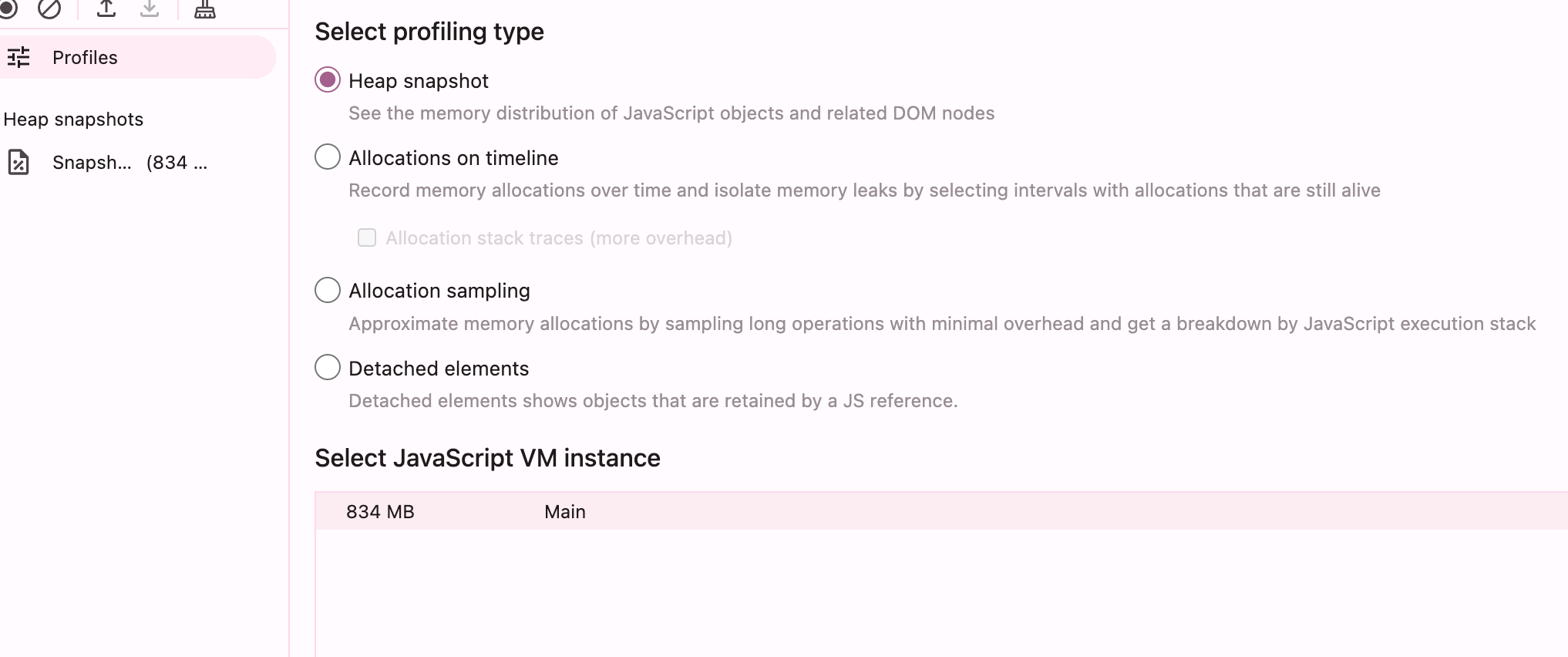
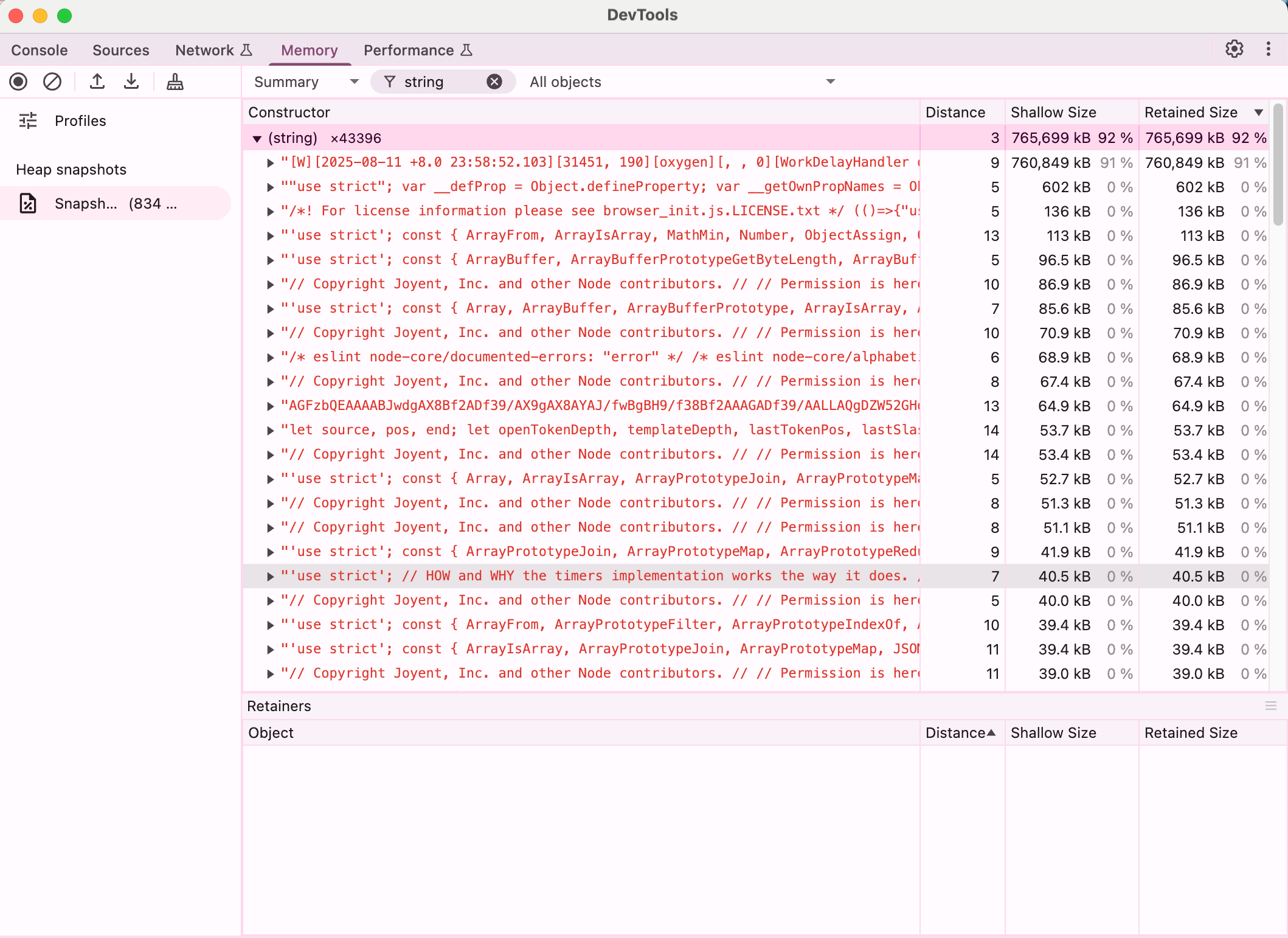
我们可以看到,一个380MB的日志文件,作为字符串加载到内存中后,实际内存使用差不多在800MB左右,且90%都是日志文件字符串数据。
而为啥380MB的大小的日志数据,加载到js中后,内存貌似翻倍了呢?这是因为文件本身是utf-8编码的(可变长度1-4字节/字符),而js中的字符串格式数据是按照utf-16进行编码的,而日志文件在大部分是英文和数字的情况下,通常一个字符是1个字节,所以,这里大致估算,如果加载一个380MB的以英文数字为主的日志文件,并将其转换为字符串进行存储,则加载后大致会占据760MB左右的内存,符合当前的内存表现。
那么我们再来看看渲染进程的内存占用,这里加载一个较小的日志文件,大约40MB
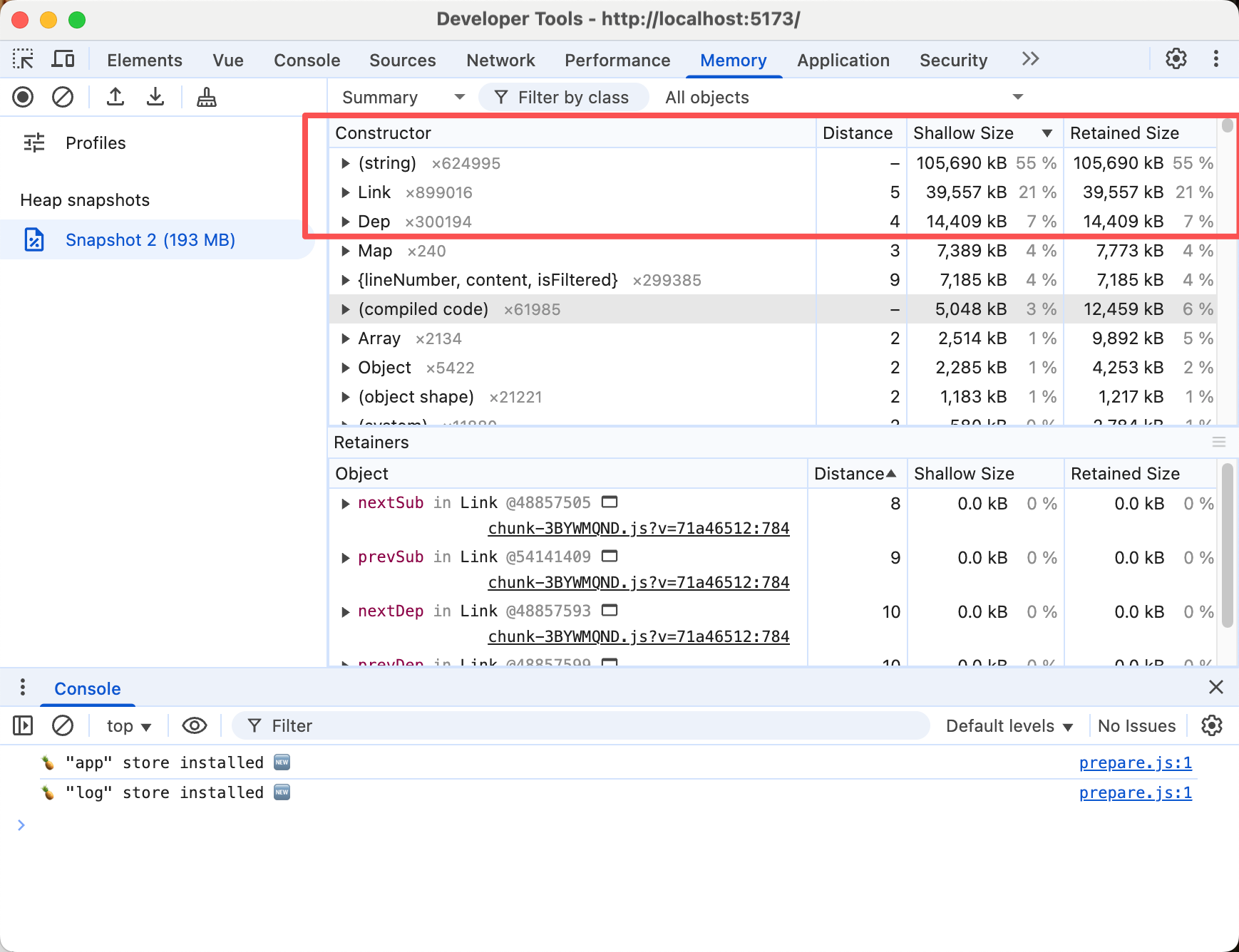
我们可以看到,整个js的内存占据了大概190MB左右,其中字符串数据占据了一半多,而其中还有一个Link和Dep实例占据的内存也不少,将近30%,这个是什么呢?其实查看一下Link对象的内容,再问一问AI,大致可以推断出它是Vue3响应式系统中用于建立依赖关系的内部数据结构。
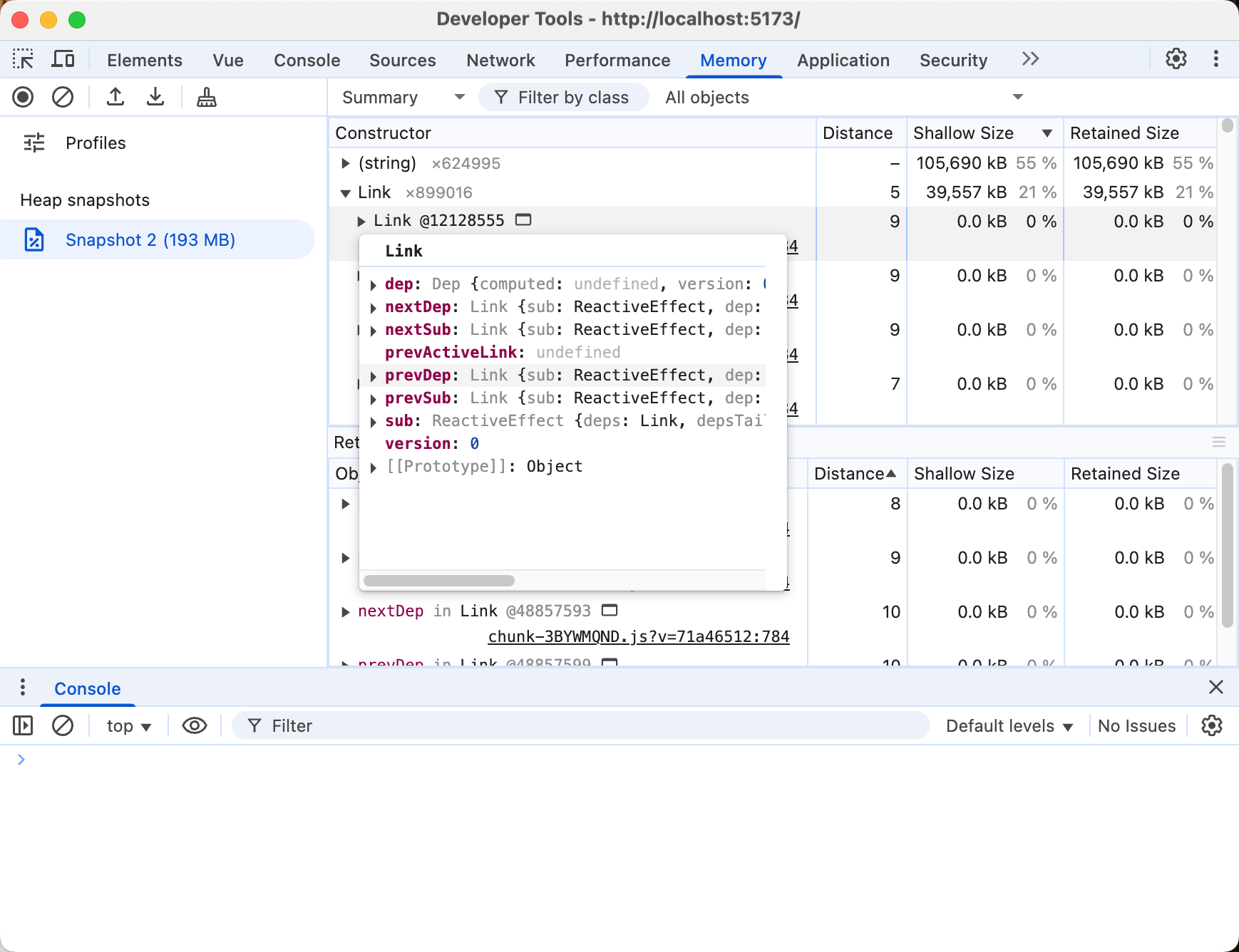
这里其实是在使用Vue3时,处理大数据数据时容易忽略的性能问题,vue3的响应是默认是会深度的对数据进行依赖追踪,如果你是单纯的将大数据数组包含在ref中,那么其响应式系统的依赖追踪可能会产生不小的性能负担,内存就是一方面。
那么如何对其进行优化呢?上面的方案其实暴露了如下问题:
- 主进程加载日志数据后,再通过ipc传递给渲染进程,且是全量的,那么会导致数据存在两份,这对于占据大量内存的日志文件来说非常致命
- 日志数据加载为js字符串后,内存占用翻倍
- 在vue3中,对于大数据的处理不当,同样也会对其性能方面产生不小的负担
关于上面的问题,我们需要从整体来解决,其中vue3的大数据性能问题,vue3官网也给出了一些解决方案了,例如对大数据使用shallowRef()和shallowReactive(),vue3官网参考
处理后的结果:

不过,对于这一部分我并没有深入,因为如果要真正的将内存给降下来,单纯仅仅解决vue3的大数据性能问题是不够的,更多的瓶颈还是在js字符串转换和存在多个字符串副本的问题。
当然,在处理内存问题的同时,也仍然要考虑和权衡浏览和过滤时的性能问题。
性能问题
上面聊到了内存方面的问题,这次同样要聊一下性能方面的问题了。性能上的问题,简单一点可以直接从体感上就可以注意到:
- 在渲染进程打开一个380MB的日志文件时,整个ipc接口的调用耗时在1500ms以上,而打开一个40MB大小的日志文件时,耗时在300ms,总之,文件越大,渲染进程从主进程获取日志数据的时长就会越长,通常这是ipc通信在处理结构化克隆大数据时所耗费的时间。
- vue3在处理大数据时的响应式系统性能(上文已经提到)
- 过滤时的性能
其中第1和第2点影响的是从用户点击文件列表,到打开一个tab并看到其内容的时长,在未优化的情况下,可以非常明显的感觉到其耗时非常的长。而第3点则是过滤时的性能,这个我们后续再展开。
优化:数据动态加载
既然目前整个方案中的数据流转和传递存在性能问题,那么就可以考虑换一种数据加载方案,通常针对这种大数据,懒加载算是一个常用的优化方案,这里用到的是类似懒加载的动态加载,那么如何做呢?
我们针对大数据的浏览使用了虚拟滚动,来显示当前区域的元素,避免全量渲染数据dom导致页面卡顿的问题,那么我们是否可以基于虚拟滚动需要显示哪些数据,就动态加载哪些数据,这样避免了一次性全量将日志数据从主进程传递到渲染进程,同时由于数据是的动态的,vue3的响应式系统也不会因为数据量过大从而产生性能瓶颈(不过相应的优化还是要做的):
- 当打开一个日志文件进行浏览时,不需要通过ipc来获取主进程中的完整日志数据,只需要知道日志数据有多少行,并根据行数作为长度生成一个空的数组即可,这个数组仅用来填充虚拟滚动,同样需要使用类似
shallowRef()等方法来避免vue3的响应式系统在处理大数据数组时的性能问题。 - 这里我使用的是开源的虚拟滚动库vue-virtual-scroller,他有一个
update (startIndex, endIndex, visibleStartIndex, visibleEndIndex)事件,当视图更新时会触发,并提供视图相关的数据索引。 - 基于数据索引,我们可以知道当前视图显示的数据是哪些,那么就可以基于这个数据范围,去通过ipc接口请求主进程中实际的日志数据
- 而UI的渲染,只需要基于当前显示的
数据索引去匹配实际加载的日志数据并渲染显示即可 - 并且,你可以将整个数据划分成合适大小的区块,这样当视图滚动的索引位置,包含了某个区块,就加载这一整个区块的数据,这样可以减少ipc动态加载数据的频率。
- 而且,为了防止ipc动态加载的数据延迟(虽然不大)导致的快速滚动时,页面显示白屏,可以提前向上和向下加载冗余的区块数据,从而提高日志浏览时的体验。
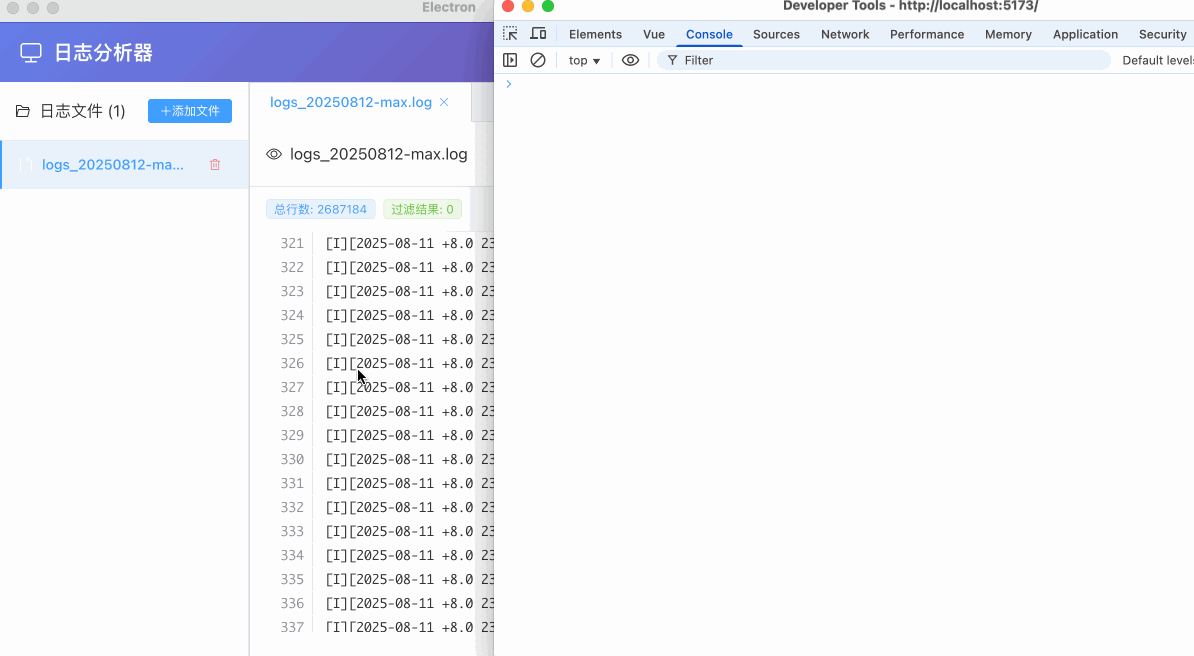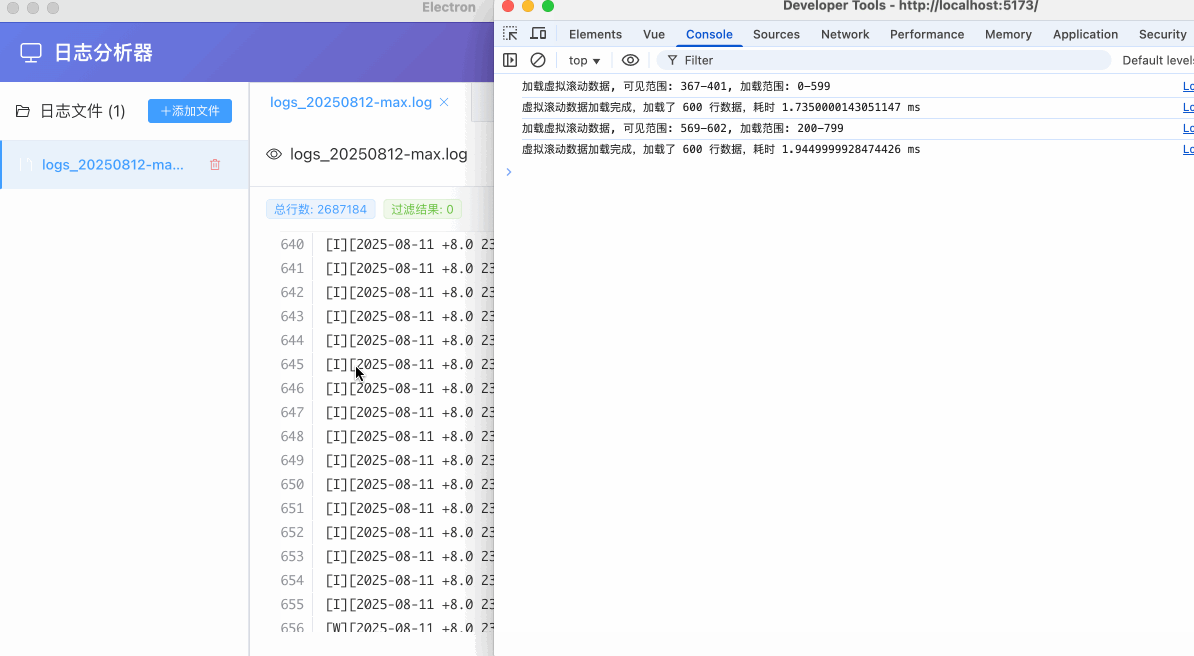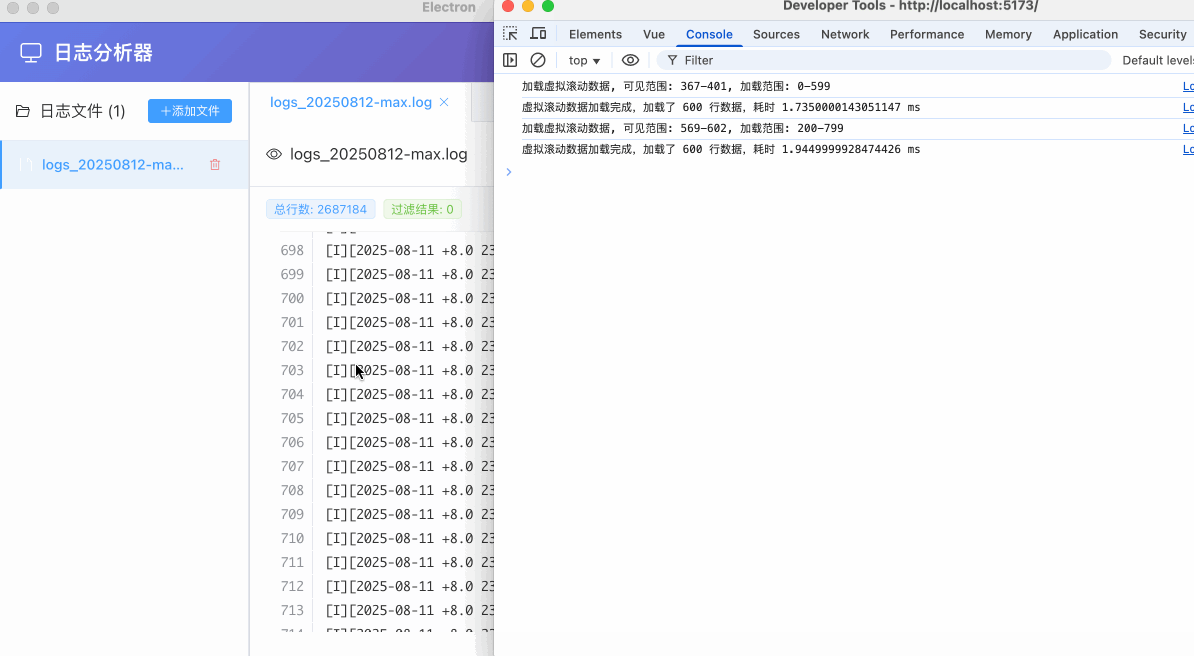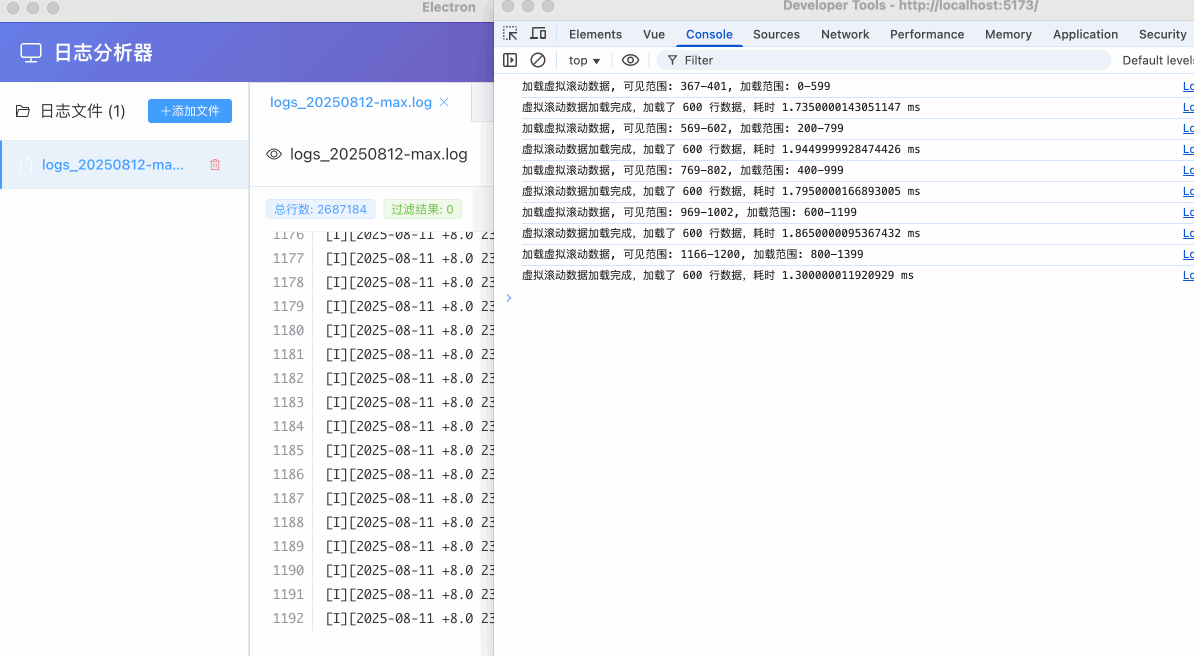
通过上面的动态加载,渲染进程在实际打开一个日志数据准备浏览时,可以跳过从ipc获取完整日志数据的过程,同时也间接避免了vue3的响应式系统在处理大数据时的性能问题。更重要的是,减少了渲染进程的内存占用,避免大数据的多份复制和其性能损耗,虽然一开始考虑动态加载时会担心其ipc时间损耗导致其浏览体验是否会有问题,不过最终效果还是能够接受的,下面是动态加载的效果和ipc耗时:
优化:buffer
上面的动态加载虽然解决了渲染进程内存过大问题,不过主进程在加载日志文件后,仍然是以字符串形式存储,内存仍然是日志文件的两倍,且在处理字符串的过程中可能会抛出这个错误:RangeError: Invalid string length(这里我用node的readFile读取了一个1.5G的日志文件,使用utf-8编码选项)
ps: 当然,这里的readFile肯定不是非常合适,毕竟对于大文件,通常用
createReadStream来创建一个stream流来处理比较合适,不过我们先一步步来处理,暂时先考虑整个文件加载到内存的情况,因为steam流式处理在这个场景也不一定是最合适的。
- 既然我们现在的日志浏览时的数据是动态加载的,那么我们也没有必要在加载日志数据时,将其作为字符串来读取,而是在渲染进程真正需要加载某一个区域的行数时,再将实际的日志数据解析成字符串返回给渲染进程即可。
- 我们可以将日志数据加载为一个buffer来存储,但是由于数据是一个完整的buffer,我们还需要解析出行数据,以便后续的渲染和数据加载。
- 我们可以遍历整个buffer的所有字节,如果判断是一个换行符
\n或者\r\n,那么就将其记录为一行,并记录该行日志数据在整个buffer中的字节偏移量,方面后续按照行信息来提取buffer中的日志数据。将所有行信息记录为一个元数据数组metadata。- 整个日志元数据数组,虽然说是一个数组,其实是一个
元组数组,并且我将其存储为了一个32位的整数buffer,其数据结构按照[offset, length, offset, length, ...]的顺序存储,可以猜猜为啥要这样干,后续会为大家揭晓。
- 整个日志元数据数组,虽然说是一个数组,其实是一个
这样,整个的流程就变成了:
- 渲染进程通过行索引,请求ipc到主进程来获取具体的行日志数据
- 主进程根据行索引,通过元数据buffer找到该行日志数据的偏移量offset和长度length
- 通过偏移量offset和长度length,读取日志数据buffer中实际的字节数据并将其转换为字符串
- 返回所有的行字符串数据给渲染进程
至此,我们在加载大日志数据时,就能够避免了日志数据转换为js字符串时可能出现的一些内存问题(内存占用翻倍或者超出v8的内存限制)
通常,面对大文件数据的处理,你可能会碰到之前很少碰到的内存问题和一些限制,例如:
- node中v8内存的限制(2G或者4G大小等等)
- buffer长度限制,数组和arrayBuffer的长度在v8中被限制在2G左右(64 位系统:单个 Buffer 最大为 2^31 - 1 字节)虽然buffer存储在node的 “堆外内存”(不占用 V8 堆内存)
虽然上述方案降低了程序自身处理大数据日志文件时的额外内存占用问题,但是仍然无法突破node本身中的一些内存限制。所以,如果还想要处理更大的日志数据文件,例如2G、5G这种(在2G的原始日志文件中排查问题是非要这么干不可吗😂),那么就需要其他的优化方案了,例如:
stream流式处理:分块读取原始日志文件,并解析其日志行的元数据mmap内存映射:将日志文件映射到虚拟内存,并且可以跨进程共享
这工作可能就没有那么简单了,后面验证成功了再单独开一篇文章来聊聊吧。
优化:过滤性能
在目前实现的过滤逻辑比较简单,仅仅是针对文本匹配来进行过滤,其实在一开始的想法是想要基于业务日志的打印规律来快速对日志文件进行过滤和筛选,以便能够针对某个业务问题快速进行分析和定位,不过在实现的过程中,重心还是放在了日志数据的处理上了,不过这个场景下,过滤模块本身的业务实现并没有那么难以扩展,由于日志数据本身的特点,单行日志数据作为一个逻辑整体,所有过滤业务都是基于单行日志本身的,它没有所谓的上下文,不管后续对日志应用怎样的过滤条件,我们都可以基于行这个概念本身去做处理,所以我们只需要处理好行本身的过滤实现即可,具体应用怎样的业务过滤实现,后续再自行扩展即可。
我们假设过存在一个过滤器,其中包含任意的过滤条件,我们先不管其过滤条件是什么、怎么去处理过滤的,我们仅知道我们提供需要过滤的日志行数据给过滤器,它能够帮我们筛选出其是否满足条件即可。
那我们现在拥有了日志数据和日志元数据(行信息),且拥有了一个过滤器,那么我们在触发过滤时,需要针对当前需要过滤的数据应用该过滤器,通常我们直接依次读取需要过滤的数据并应用过滤器来判断是否符合条件,如果符合,则将该日志的行索引将其添加到结果数组中即可。
由于过滤逻辑是纯js逻辑,可能需要遍历整个日志数据,如果日志数据量过大,则耗时可能会比较长,所以我们可以考虑将其过滤逻辑放到worker中去执行,并返回过滤后的日志行索引,且日志过滤作为无状态的逻辑处理,我们可以启动多个worker线程去并行处理。
- 启动程序时,创建并初始化worker池用于日志数据过滤
- 当对一个数据量较大的日志数据应用过滤时,基于worker池数量,逻辑拆分待过滤的日志数据作为多个过滤任务。
- 将拆分的过滤任务添加到worker池中,由worker池管理和执行过滤任务
- 等待所有过滤任务处理完成,拼接过滤结果并返回
整个的流程比较简单,算是比较常见的拆分耗时任务的方式。不过这里有个比较严重的问题:由于worker任务是无状态的,它如何接收待过滤的日志数据?如果依赖postMessage本身,那么由于结构化克隆,在面对大数据时则又会出现和主进程传递给渲染进程日志数据时导致的性能和内存问题了。
那如何解决?难道按照渲染进程那样也做一个分批次过滤来减低瞬时内存?如果这样的话,在每次worker的postMessage所执行的结构化克隆和消息通信时的损耗也许会影响整体的过滤性能,因为渲染进程的分批加载本质是一种按需加载的优化,而这里的过滤需要在一个场景中应用于所有日志数据,也许该方案在优化过滤本身的性能时可以考虑其应用场景,不过在数据传递这个问题上,还有另外一种其他更好的方案,那就是共享内存。
对于大数据的访问来说,我们自然期望它仅仅只有一份,并且能在程序的各个地方,甚至在不同线程、进程中共享,这样对于内存的使用是最高效的,而我们的场景下,是期望能在主进程和子线程中去共享内存,则我们可以考虑使用SharedArrayBuffer来实现。
SharedArrayBuffer是JavaScript原生支持的共享内存对象,允许同一进程内的多个 Worker 线程直接访问同一块内存,适用于单进程多线程场景(如 Node.js 的 worker_threads 模块)。
由于多个线程可以同时访问和修改同一块内存数据,所以通常需要配合原子操作来进行同步。不过在我们这个场景下,日志数据是只读的,所以不需要考虑原子操作。
那么基于上面的方案,其实只需要将日志数据转换为SharedArrayBuffer,并且同时将日志的metadata也存储为SharedArrayBuffer即可,改造起来非常简单。这样它们就可以在多个worker线程中共享数据,而无需进行复制,这也是之前文章中提到的,metadata本身也作为buffer存储的原因,因为如果metadata是一个对象数组,那么在传递给worker时,则避免不了结构化克隆。
其实对于ArrayBuffer来说,我们也可以通过postMessage中的第二个参数transfer来转移buffer的所有权,这样就可以避免结构化克隆算法来复制整个buffer数据。不过,这会导致主进程的buffer对象不可用,且由于存在多个worker线程同时执行过滤,但是只能转移buffer给某一个worker线程,那么就要拆分日志buffer,比较麻烦也没有必要,不如SharedArrayBuffer直接共享来的方便。
还需要注意一点的是,在worker中进行过滤时,内部也不会将日志数据一次性转换为字符串再进行过滤,而是依次读取数据并过滤或者按照行进行分块读取并过滤,同样是避免一次性转换太多字符串数据导致的内存峰值过高。
最终的一个过滤性能,简单的验证了一下,对1.5GB大小、1000w行的日志数据进行文本过滤:
- 筛选出990w行:多线程worker耗时在500ms左右,单个worker耗时在2500ms左右
- 筛选出450w行,多线程worker耗时在400ms左右, 单个worker耗时在2200ms左右
- 筛选出4000行,多线程worker耗时在250ms左右,单个worker耗时在1800ms左右
其时间上的差别可能还是在于结果是以行索引数组进行返回的,所以筛选的结果越大,返回结果时的postMessage耗时越高。不过后续可以再进一步优化,如果后续它成为新的性能瓶颈的话(其实这种情况下,将结果存储为一个buffer,用上文提到的buffer所有权移交,然后主进程再将其转换为数组的性能可能会更好,甚至都可以不用转换,反正渲染进程浏览是动态加载的,动态计算就好)
其他
其实在日志的数据浏览中,有一个暂时不好解决的问题,那就是vue-virtual-scroller没有处理浏览器对dom高度的限制,且滚动是基于dom本身的滚动条,如果你的数据量过大,那么就会导致其dom高度超出了浏览器dom最大高度的限制(因为dom受限浏览器最大高度,故滚动也受限于该高度),从而无法显示完整的内容(以24px为行高,大约是只能显示68w行)。从网上查找了一下,发现并没有太好的解决方案,如果有几个方向:
- 在一开始我的处理方法是分割大文件为多个较小的子文件(大约每个文件50w行)来显示,它属于逻辑分割,且将每个buffer也按子文件分割并分别存储。不过后来发现如果这样做,会导致过滤时无法对整个文件进行过滤,即使能对整个文件进行过滤,也要判断过滤后的结果是否也需要分割,处理起来比较麻烦。
- 后来我的另外一个思路是,文件本身不进行分割,而是在渲染进程中对数据的显示进行分割,即将显示的逻辑按照50w行为一个块,当用户浏览到某个块的最后一部分时,可以选择跳转到下一个块进行浏览。这样的好处在于,过滤时不需要关心文件分割的问题,同时渲染进程分块的逻辑不需要关心处理的是数据是否是过滤后的数据还是过滤前的,这样能让分块的逻辑解耦,虽然这同样会让用户在浏览日志数据没有那么连贯。
- 或者自行实现虚拟滚动,且自行实现虚拟滚动条,这样可以绕过浏览器dom最大高度限制
- 或者可以考虑用直接用vscode自身的编辑器组件:monaco-editor,它是对大数据进行了分块的,并且处理了dom最大高度限制问题。
我觉得最后一个方案可以尝试尝试。
总结
以上就是我基于electrong-vite实现的大日志文件浏览、过滤应用的整个过程了,其中的代码细节并没有放出来,因为感觉并非重点,重点在于实现过程的整个思路以及逐步优化过程的一些思考和尝试。
当然其中有些方案还没有来得及实现和验证,尤其是对更大文件的加载处理(例如mmap内存映射)和monaco-editor的接入是否能够在性能和功能上达到自己预期的效果,我感觉还是值得期待的。如果这两个方案验证成功了,那么后面就可以考虑基于实际业务去做真正的日志分析了。敬请期待。